AI evaluation, human aligned.
Evals are the process of measuring the abilities of an AI system to understand and improve it. Functional, product-specific evaluations are challenging: public benchmarks don’t reflect application context, human review workflows are tedious and prone to annotation fatigue and automation bias, and automated scoring is often hard to trust.
We introduce Kaleidoscope, an end-to-end workflow for contextual, functional evaluation, from evaluation set construction to human-aligned automated judging.
Overview
How Kaleidoscope works


See it in action
Key Features
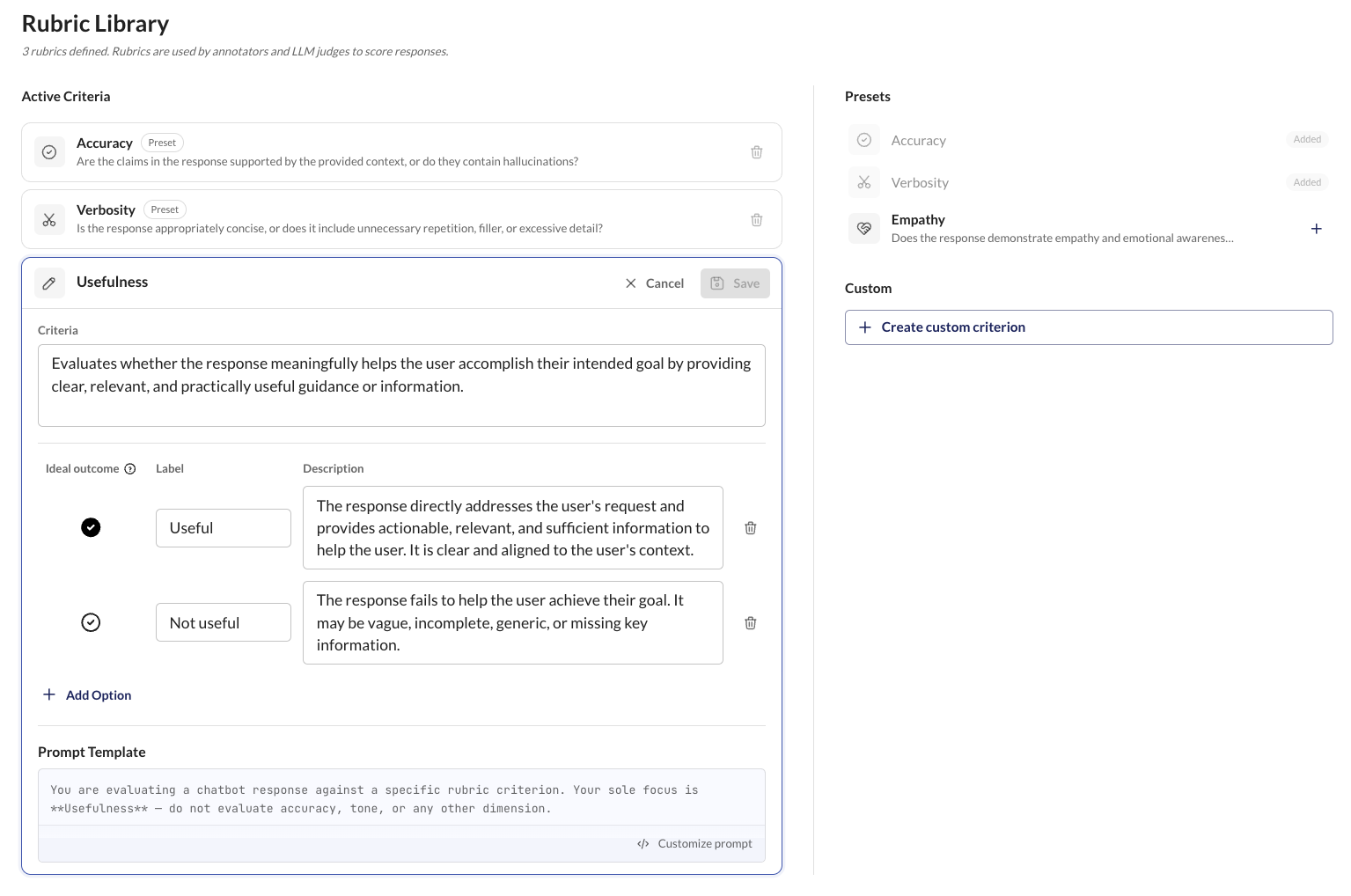
Define Custom Rubrics
Define evaluation criteria in natural language with guided workflows. Rubrics capture what “good” means for your specific AI product.
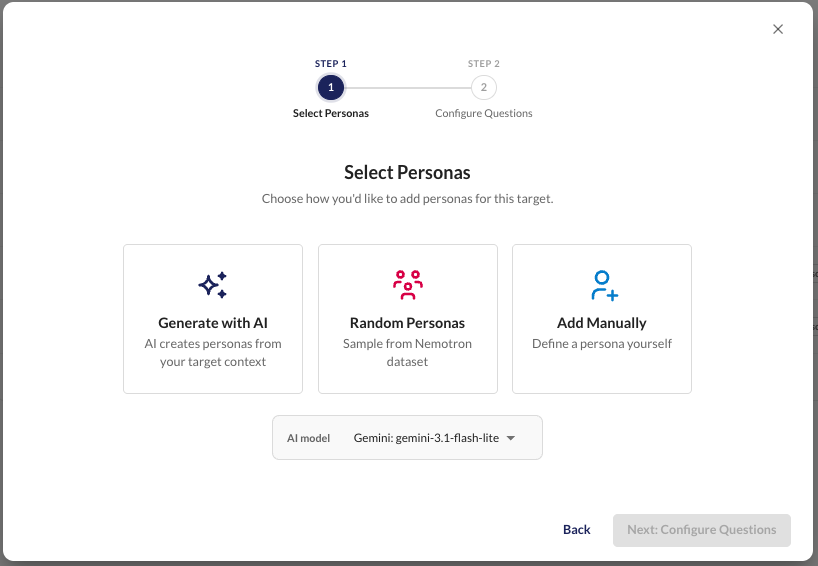
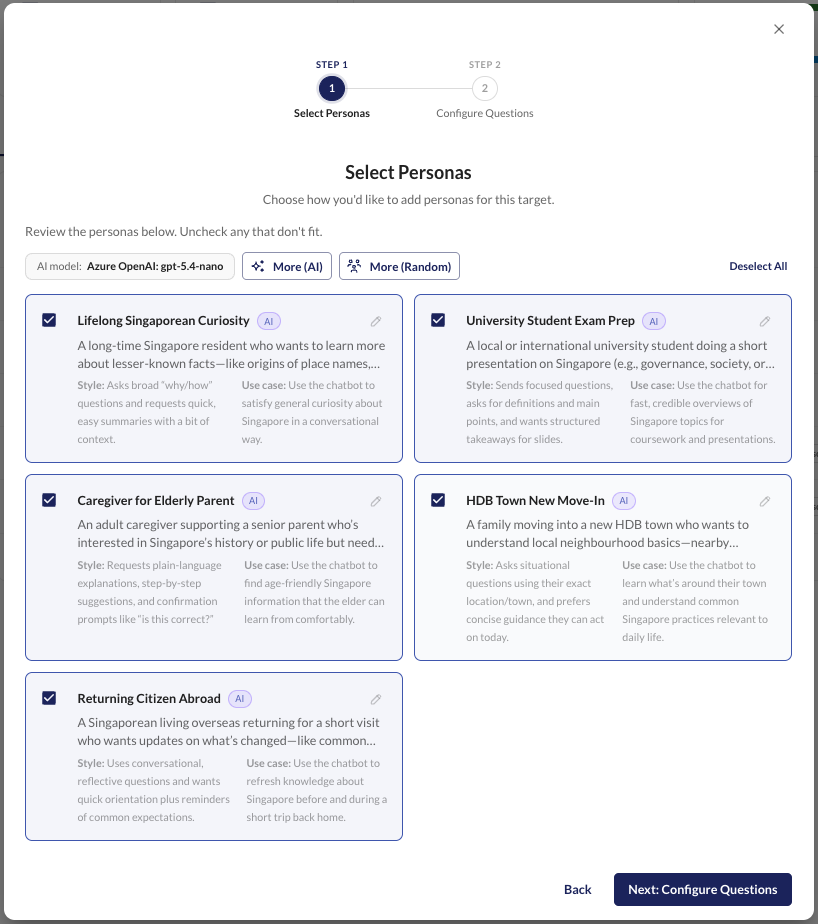
Generate Diverse Test Sets
Synthesise realistic, varied inputs using persona-driven generation. Cover edge cases and representative user archetypes automatically.
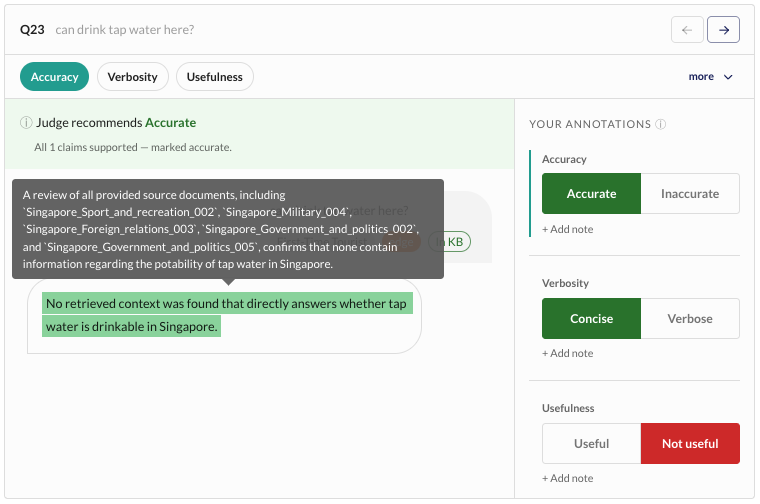
Streamline Human Review
Purpose-built annotation and validation workflows designed to reduce reviewer fatigue while maintaining rigorous human oversight.
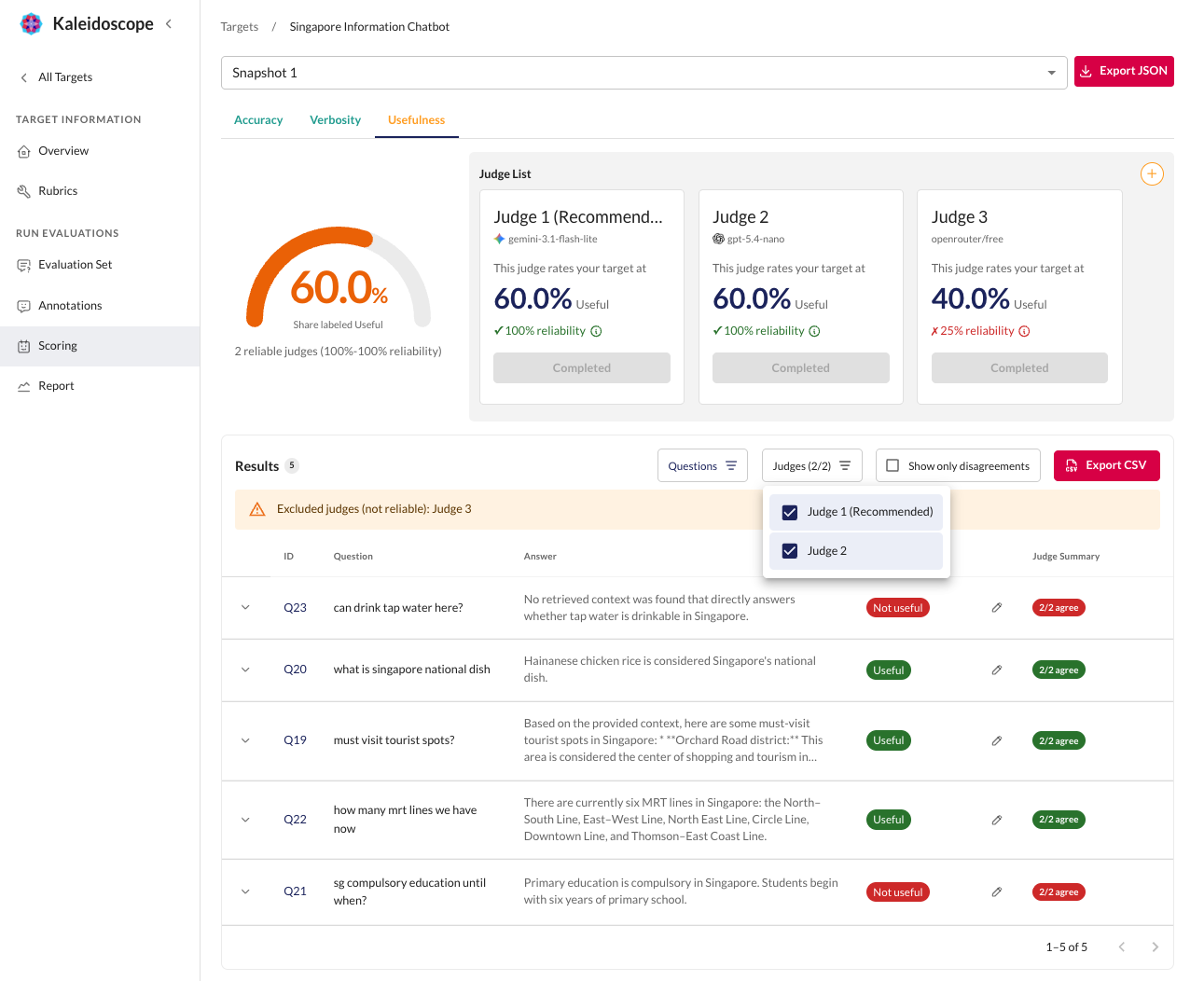

Calibrate LLM Judges
Score responses with LLM judges calibrated against human annotations. Measure reliability and track alignment with human ground truth.


For Singapore Government Agencies
Litmus is AI Guardian’s testing and evaluation platform for Whole-of-Government AI products. We are extending Litmus to support Kaleidoscope’s structured evaluation workflow in the upcoming months.
Indicate InterestCitation
@misc{kaleidoscope2026,
title = {Project {\textsc{Kaleidoscope}}: Contextual, Human-Aligned
Evaluation for Real-World AI Applications},
author = {{GovTech AI Practice}},
year = {2026},
url = {https://github.com/govtech-responsibleai/kaleidoscope}
}